2. POLYSYS-Peru¶
2.1 Introducción¶
El cambio climático. constituye la mayor amenaza medioambiental a la que se enfrenta la humanidad; en ese contexto representa un desafío para los diversos sectores de la sociedad (academia, gobiernos, empresas, etc.) y por tanto es primordial comprender que si se continua por la senda actual el estilo de vida de las personas cambiará, forzosamente, hacia menores niveles de vida. Para evitar llegar a un estado de daño irreparable, a mediano plazo, el objetivo imprescindible es alcanzar la meta de “no incrementar la temperatura global en más de 1.5 ºC” . Arribar satisfactoriamente a esta meta es imperante toda vez que se traducirá en evidentes beneficios para la conservación de los ecosistemas naturales. Sin embargo, para conseguirlo es necesaria una cooperación internacional donde los intereses particulares de las naciones pasen a un segundo plano y sea posible priorizar el análisis de la problemática medioambiental en colectivo, en efecto, sobre los líderes del mundo la responsabilidad de tomar las medidas pertinentes para evitar una catástrofe irremediable.
El resultado ideal de la propuesta previa es que una política cooperativa se traduzca en una coordinación mundial donde los países desarrollados actúen como líderes, marcando pautas a seguir y estableciendo compromisos con el resto de las naciones. Este liderazgo se fundamenta en múltiples aspectos, iniciando por la mayor capacidad de recursos tanto económicos como técnicos, así como en un mayor grado de representatividad en las cuotas de emisiones globales. Sin embargo, esto no exenta de responsabilidad a los países en desarrollo, por el contrario, su compromiso es igualmente primordial toda vez que a largo plazo, si no se hace nada, se convertirían en las principales fuentes de contaminación ambiental.
Con base en lo anterior se puede mencionar los ejemplos de China e India, ambos países en vías de desarrollo, pero con una amplia producción industrial, la cual genera la mayor cantidad emisiones en el mundo (AIE, 2015). Por supuesto estos ejemplos se presentan sin perjuicio de minimizar la responsabilidad de aquellos países en vías de desarrollo con menores niveles de producción industrial. De esta manera es importante también recalcar otras características de dichos países que son importantes en materia ambiental, posiblemente la más preponderante relacionada al stock forestal .
Como ya se mencionó la meta “del +1.5 ºC” es un objetivo de mediano plazo por lo tanto requiere tomar medidas en el presente de tal forma que sea creen los cimientos necesarios para conseguir resultados claros en el mediano plazo. Lamentablemente el forjamiento de estos cimientos se muestra como poco atractivo para el sector político, que suele tomar decisiones basadas en expectativas que no superan los 5 años. De esta forma muchas las medidas necesarias para cumplir la meta “del +1.5 ºC” serían vistas como costosas no solo en dinero, sino también en popularidad.
Por otro lado, los países en desarrollo están tentados a industrializar sus economías a costa de una fuerte depredación de sus recursos naturales, siguiendo un camino similar al de sus pares desarrollados en el pasado. Claramente, para países con bajas capacidades de investigación y desarrollo y, en consecuencia, baja innovación en sectores como la industria o los servicios tecnológicos, la explotación de los recursos naturales se presenta como una opción simple y rápida para la generación de riqueza o en algunos casos como medio de escape a la pobreza. Por lo tanto, tomando en consideración todos los argumentos planteados hasta este punto se deduce que recae una fuerte responsabilidad sobre los analistas y técnicos de distintas ramas poder hacer propuestas que permitan equilibrar el crecimiento económico con el cuidado del medioambiente, procurando en el camino la generación de bienestar para la población más vulnerable.
Las propuestas técnicas requerirán ser fundamentadascon investigaciones y análisistanto de carácter cualitativo como cuantitativo, asi como adaptarse plenamente a la realidad del país que recibe recomendaciones. Para ello es de suma importancia considerar la heterogeneidad de las naciones, considerado incluso aspectos culturales hasta la descripción de la estructura productiva, en tal sentido es necesario que las políticas cooperativas de preservación ambiental incorporen las consideraciones de cada región de forma tal que permitan equilibrar el crecimiento económico con el cuidado del medioambiente, procurando en el camino la generación de bienestar para la población más vulnerable.
En ese contexto, se presenta este documento en que se pretende simular y analizar sobre el comportamiento de la economía peruana, y utilizar esos resultados como una herramienta para evaluar politicasy pronósticos sobre el cambio climático futuro generado por las actividades económicas peruanas. Concretamente nos enfocamos en los efectos de cambio de uso de suelo, relacionado con la agricultura, ganadería y silvicultura.Asimismo,las contribuciones de las emisiones del sector energético, relacionadas principalmente con el transporte. Nuestro artículo presenta características económicas peruanas y pretende comprender esas cualidades que hacen que el caso peruano sea especial y diferente de otros países similares en la región.
Este documento está organizado de la siguiente manera. Primero, se presenta una introducción y una descripción de la situación del Perú en materia económica y ambiental. El segundo capítulo está dedicado a detallar los aspectos teóricos de la modelación . El tercer capítulo incluye una documentación de la programación del modelo, así como todas las fuentes de información, incluidas las bases de datos y otros resultados de documentos utilizados como inputs del modelo POLYSYS. En el quinto capítulo se presenta un resumen de los resultados en todos los sectores. Finalmente en el sexto capítulo concluimos. Este documento está organizado de la siguiente manera. Primero, se presenta una introducción y una descripción de la situación del Perú en materia económica y ambiental. El segundo capítulo está dedicado a detallar los aspectos teóricos de la modelación . El tercer capítulo incluye una documentación de la programación del modelo, así como todas las fuentes de información, incluidas las bases de datos y otros resultados de documentos utilizados como inputs del modelo POLYSYS. En el quinto capítulo se presenta un resumen de los resultados en todos los sectores. Finalmente en el sexto capítulo concluimos.
2.1 Estructura¶
El caso de la economía peruana es interesante porque su contribución al cambio climático depende no solo de la industria sino también de otros sectores como la agricultura, la ganadería y, por supuesto, la deforestación en la selva tropical. Esto es problemático porque muchas de estas actividades económicas están asociadas al comercio en pequeña escala constituido principalmente por individuos con baja acumulación de capital humano y, en consecuencia, cualquier política no bien analizada podría afectar la vida de las personas que constituyen un grupo vulnerable en el país. Esto es diferente a otras economías en desarrollo que se concentran en otro aspectos, por ejemplo en cuestiones energéticas.
Con respecto a las fuentes contaminantes en el país se puede mencionar que las emisiones nacionales de gases de efecto invernadero (en adelante abreviadas como GEI) de 2010 en Perú representaron solo el 0.3% de las emisiones globales (MINAM, 2010); y sus emisiones per cápita fueron más bajas que el promedio de América Latina y el mundo. Estas características están asociadas a una economía cuyo sector de generación de energía utiliza energía limpia, principalmente energía hidroeléctrica, además la industria no está altamente desarrollada. La principal fuente de emisión de la quema de combustibles fósiles toma lugar en el sector transporte.
Perú podría considerarse un país altamente vulnerable a los efectos del cambio climático, ya que tiene las siguientes características: área costera baja, tierras áridas y semiáridas, áreas propensas a inundaciones, sequías y desertificación, ecosistemas de montañas frágiles, áreas propensas a desastres, áreas con alta contaminación atmosférica urbana y economías altamente dependientes de los ingresos generados por la producción y el uso de combustibles fósiles, es decir, , es decir, presenta 7 de las 9 características que vuelven vulnerable a un país al cambio climático. Debido a su alta vulnerabilidad a los efectos del cambio climático, las contribuciones de Perú buscan mantener un equilibrio entre las acciones de adaptación y mitigación.
En la actualidad,Perú ya ha definido su contribución nacional (NDC) para cumplir con los compromisos asumidos como resultado del Acuerdo de París.El gobierno peruano espera una reducción del 30% de las emisiones en relación con un escenario BAU en 2030.Lasl NDCs de Perú incluyen acciones tanto de adaptación y mitigación para los cuatro sectores analizados aquí.
Para realizar las estimaciones previamente mencionadas aquí se utiliza el modelo POLYSYS; una herramienta práctica que sirve para analizar políticas de alto impacto en el sector agrícola. Este análisis ayuda a establecer vínculos entre los indicadores económicos y el desempeño de la política ambiental. Por ejemplo, en la agricultura, para cualquier cultivo en particular, permite asociar el número de hectáreas cultivadas con un volumen determinado de emisiones de efecto invernadero, de esta horma un incremento en el número de hectáreas cultivadas implica un incremento en las emisiones. Los resultados del POLYSYS son especialmente útiles como pautas para la toma de decisiones .
En el modelo POLYSYS se establecen sistemas de ecuaciones simultáneas donde las incógnitas representan variaciones en variables endógenas que se resuelven ante cambios en las variables exógenas del modelo. El resultado representa al mercado en equilibrio y la senda generada funciona como línea de base . En este punto, la generación de escenarios implica que el equilibrio se vea afectado de manera exógena por perturbaciones, y los resultados se guardan como los resultados de las políticas que se busca analizar, generando sendas alternativas a la de equilibrio.
El modelo considera por el lado del consumo las elasticidades, tanto precio, como cruzadas y de ingreso, las cuales representan las preferencias de la población. Así los cambios proporcionales en las variables exógenas determinan el efecto acumulado de los cambios en el paquete de variables exógenas para cada escenario, incluyendo variaciones en las variables de consumo de los distintos bienes.
La dinámica del POLYSYS consiste en utilizar funciones de oferta constantes en cada año pero que varían de periodo a periodo, adaptándose a las condiciones de mercado, basados en los resultados de mercado del año anterior. Para ello el POLYSYSIS busca simular como un agricultor representativo en una determinada región toma la decisión de cultivar determinada canasta de productos agrícolas. Esta simulación implica representar una función de beneficios sujeta a restricciones de capacidad y flexibilidad. Para ejemplificar mejor la dinámica del modelo consideremos que en una región solo se cultivan dos productos a y b; luego un agricultor asentado en dicha región tendrá la siguiente función de beneficios de cultivar los dos productos:
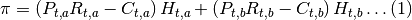
Donde 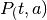 representa el precio del cultivo a,
representa el precio del cultivo a, 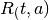 representa el rendimiento (número de kg producidos en una hectárea del producto a),
representa el rendimiento (número de kg producidos en una hectárea del producto a), 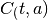 representa el costo por hectárea de cultivar el producto a y
representa el costo por hectárea de cultivar el producto a y 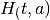 representa el total de hectáreas cultivadas del producto a. El caso para el producto b es análogo, y como se puede observar el beneficio del agricultor se constituye por la venta de los dos cultivos disponibles. Claramente el total de tierra del que dispone el agricultor es la suma
representa el total de hectáreas cultivadas del producto a. El caso para el producto b es análogo, y como se puede observar el beneficio del agricultor se constituye por la venta de los dos cultivos disponibles. Claramente el total de tierra del que dispone el agricultor es la suma 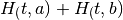 y no podrá cultivar más allá de este nivel. En todos los casos el subíndice t representa el tiempo y está indicando que nos encontramos en el periodo actual t.
y no podrá cultivar más allá de este nivel. En todos los casos el subíndice t representa el tiempo y está indicando que nos encontramos en el periodo actual t.
Se tiene entonces que un agricultor recibirá como beneficio el margen neto, por hectárea, de cada cultivo multiplicado por el número de hectáreas cultivadas de cada cultivo. Si se piensa en este agricultor como el agricultor representativo o promedio de una región y posteriormente se agregan todos los agricultores en dicha región entonces podremos observar que la ecuación (1) también puede representar la función de beneficios de las actividades agrícolas en la región. Los agricultores tomarán en consideración la función (1) cuando decidan como asignarán la tierra entre los cultivos disponibles y por tanto lo que harán será optar por cultivar los más rentables.
La forma funcional de la ecuación (1) es un problema de programación lineal (LP). En general los problemas de LP, sinrestricciones, tendrán una solución de esquina, esto implicaría que solo se cultivase un producto. Intuitivamente esto es lógico toda vez que el agricultor preferirá cultivar el producto que le deje la mayor ganancia, y por ende, en general la región, se especializaría en un solo producto. En ausencia de alguna restricción sobre la función (1) el resultado de esquina previamente mencionado tomaría lugar sin importar el número de productos que se oferten en una región. Esto sería contra intuitivo ya que reduciría la oferta de todos los productos a 0 con excepción de un producto, o grupo de productos en caso existan varios con la mayor rentabilidad, algo que no se observa en la realidad.
Para solucionar el problema de los resultados de esquina es necesario incluir restricciones en las capacidades de variación de la tierra asignada a cultivar los diversos productos a analizar. Es decir que hay que limitar
y 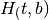 en la optimización de forma tal que ninguno pueda tomar el valor de 0. Para solucionar este problema se propone la siguiente forma del problema de LP:
en la optimización de forma tal que ninguno pueda tomar el valor de 0. Para solucionar este problema se propone la siguiente forma del problema de LP:
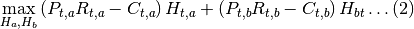
sujeto a
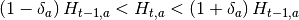
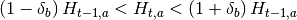
Se puede observar que las restricciones de tierra están determinadas por valores de asignaciones previas de la tierra. Intuitivamente estas restricciones lo que muestran es que una región tiene cierto grado de capacidad de cambio en la asignación de cultivos de un periodo a otro, indirectamente lo que se está modelando es una flexibilidad de oferta en la cual una variación en el precio, y por ende en la rentabilidad, genera una variación en la producción.
Usualmente la dinámica agrícola replica el comportamiento de una inversión de corto plazo donde se realiza un desembolso al inicio de un periodo y se tienen resultados al final de este. En este sentido los ciclos vegetativos suelen conllevar meses o hasta un año desde la adecuación de la tierra hasta la etapa de cosecha. En este sentido si bien es cierto la función de beneficios (2) indica que la decisión de cultivar algún producto agrícola depende del precio, lo cierto es que al momento de decidir qué productos cultivar, los agricultores no saben a cuanto lo podrán vender y por tanto los valores P_(t,a) y P_(t,b) en realidad son valores esperados.
Existen muchas formas de considerar los precios esperados, usualmente se toma un valor ponderado de los últimos periodos, dándole un mayor peso al precio del periodo anterior. Otra forma puede ser utilizando alguna función que genere una expectativa lógica de cómo pueden ser los precios en el periodo t. Luego el problema de optimización se presenta de la siguiente manera:
![\max _{H_{a} H_{b}}\left(E\left[P_{t, a}\right] R_{t, a}-C_{t, a}\right) H_{t, a}+\left(E\left[P_{t, b}\right] R_{t, b}-C_{t, b}\right) H_{b t} \ldots(3)](_images/math/91ff01ab770bb30f7afa06f073620347d41bcc09.png)
sujeto a
Finalmente los resultados para cada región permiten determinar la asignación de tierra entre la canasta de cultivos y por ende se puede determinar la oferta de los productos. En este sentido es posible hallar como varían las ofertas de los distintos cultivos, estas se denotan como
y .En el modelo POLYSYS la demanda toma una posición más pasiva en el sentido que a diferencia de generar una demanda diferente para cada periodo, se utiliza una única demanda nacional que se adapta, en el tiempo, a las condiciones de la oferta. En este sentido la demanda está representada por una matriz de elasticidades precio y elasticidades cruzadas entre productos que permiten entender como variaciones de la oferta de productos generará variaciones en el equilibrio de mercado.
Para entender mejor esto regresemos sobre el ejemplo de la sección previa donde solo existen dos productos agrícolas en una región determinada se tiene que la matriz de elasticidades toma la siguiente forma:
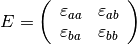
Luego se puede generar la siguiente ecuación de variaciones en la demanda:
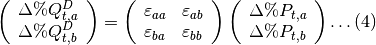
Donde el vector del lado izquierdo de la ecuación representa cambios porcentuales de la cantidad demandada de los productos a y b. Como se puede observar, las variaciones porcentuales en la demanda dependen de las variaciones porcentuales en los precios ajustadas por las elasticidades.
El equilibrio en este mercado toma lugar cuando se intersectan la oferta y la demanda. Ademas, existen dos casos, el primero, cuando un producto agrícola es transable y, el segundo,cuando no lo es. Por ejemplo, en el caso previo, donde solo hay dos productos  y
y 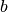 , supongamos que ambos son no transables. Luego la limpieza del mercado implica que:
, supongamos que ambos son no transables. Luego la limpieza del mercado implica que:
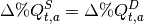
Por lo tanto, en cada iteración, cuando el agricultor decida la asignación de tierra, está decidiendo cuanto va a producir lo cual al mismo tiempo está indicando cuanto se va a demandar y consumir.

Figura 1 - Imagen 1
Cuando un bien es transable, entonces, poder determinar cuanto se va a consumir, depende de las variaciones del precio de dicho bien; dado que se trata de productos transados en el mercado internacional el equilibrio se determina por la interacción de la oferta y demanda agregadas del mundo en ese sentido el modelo requiere importar dichos resultados de mercado toda vez que el modelo no incorpora una metodología para predecir precios ni niveles de producción globales.
La simulación del sector ganadero se realiza considerando una función logística que permita simular una tendencia general de la población ganadera en la región. Sin embargo, dado que el valor que toma población en este sector se ve afectada por otras variables de índole, principalmente, económico la función logística aquí propuesta incorpora shocks de estas variables. Para comprender mejor esto, supongamos que en una región cualquiera se quiere analizar la población ganadera, luego se tiene la siguiente función logística:
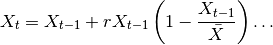
Donde X_t representa el total de cabezas de ganado en el momento t. Es decir, el stock de ganado en el presente depende del stock de ganado en el periodo anterior X_(t-1), de una tasa de reproducción natural r y de una capacidad máxima de soporte poblacional X ̅. Aunque la función (5) permite generar una guía tendencial de cómo se comporta la población de ganado, lo cierto es que no permite observar posibles fluctuaciones de corto plazo, en ese sentido se realiza un ajuste de tal forma que se obtiene el siguiente modelo:
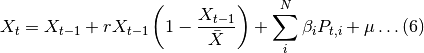
Donde el elemento de la sumatoria en el lado derecho de la ecuación (6) representa los efectos de los distintos shocks sobre la población bajo estudio. Estos shocks son diversos, por ejemplo precios de insumos, precios de los animales vivos, etc.
La dinámica de la demanda en el sector ganadero es similar a la previamente expuesta en el sector agrícola. Supongamos que solo hay dos especies criadas en una región, x y y, luego se considera la siguiente matriz de elasticidades:
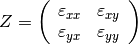
Luego se puede generar la siguiente ecuación de variaciones en la demanda:
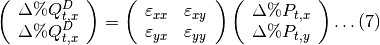
A diferencia de la sección agrícola donde se podía calcular precios locales en el caso de los productos no transables.Para el caso de las carnes el Perú requiere importar carnes de todo tipo y por tanto el precio internacional tiene una alta importancia sobre las decisiones de consumo locales, por ello, se cuenta con una serie que indica como se moverán los precios internacionales y con ellas poder hacer los cálculos para el consumo de bienes en el sector ganadería.
En el capítulo anterior se presentaron las formalidades matemáticas del modelo POLYSYS. En este capítulo, se explicarán en cambio, explicaremos los detalles metodológicos, especificando los arreglos que se hicieron en la data disponible así como indicaremos las fuentes de información necesarias para poder aplicar el modelo expuesto en el capítulo 2.
El punto de partida para la simulación con el modelo POLYSYS para Perú es dividir el país bajo análisis, en pequeñas porciones de tierra, tal que dicho espacio tenga en todos su puntos de producción características productivas homogéneas en el sector agrícola y ganadero. Esta división debe incorporar, también, las limitaciones de datos que tenga el país. En este sentido se decidió dividir al Perú en 7 regiones: costa norte, costa centro, costa sur, sierra norte, sierra centro, sierra sur y selva.
Por otro lado, la elección de la canasta de productos que utilizará debe ser escogida con sumo cuidado toda vez que esta debe ser representativa de la estructura productiva y de consumo del país. Al respecto Seminario (2018) utiliza una clasificación de productos agrícolas basada en “Clasificación Nacional de Productos Agrarios” (CNPA). Su clasificación agrupa 160 productos agrícolas en seis grupos:
Tubérculos y raíces
Frutas
Vegetales
Producción industrial
Alimentación animal
Granos y cereales
Esta agrupación se muestra muy atractiva, sin embargo, resulta insuficiente para la simulación del POLYSISPOLYSYS ya que no permite distinguir claramente entre productos transables y no transables en el sector agrícola; además existen algunos productos que, sin ser agrupados, tienen una importancia relativa muy importante en el valor de la producción agrícola, siendo más atractivo poder hacer una simulación que permita observar de manera más directa una evolución de dichos cultivos. Por estos motivos finalmente se consideró la siguiente categorización:
Alfalfa
Legumbres
Maíz
Tubérculos
Frutas de consumo doméstico
Vegetales de consumo doméstico
Frutas de exportación
Vegetales de exportación
Cacao y café
Maíz amarillo duro
Caña de azúcar
Arroz
Algodón
Cereales y granos
En el gráfico 1 se puede observar la división que se propuso, así como los productos incluidos en cada región.
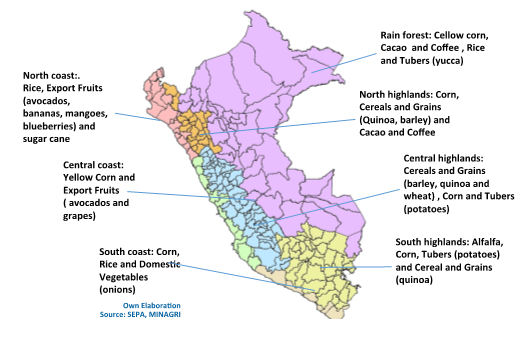
Figura 1 - Imagen 2
En el caso de la ganadería, en el Perú se consume principalmente carne de pollo y de res, por ello, se simula ambos tipos de animal. En el caso de la carne de res, se hace la distinción entre vacas cárnicas y lecheras con el objetivo de poder hacer una diferenciación entre las dos ofertas. Luego se tiene la siguiente categorización:
Vaca cárnica
Vaca lechera
Aves
Como se ha mencionado, las bases de datos con información detallada sobre el desempeño del sector agrícola y ganadero peruano, y que simultáneamente sean confiables, son escasas. Las mejores opciones son aquellas bases de datos gubernamentales (estimaciones) publicadas por diferentes instituciones públicas, especialmente el Ministerio de Agricultura y el Ministerio de Medio Ambiente. Estas bases de datos suelen ser, en gran medida, aproximaciones. El POLYSYS Perú utiliza fundamentalmente cuatro fuentes de datos diferentes: SEPA, ENA, CENAGRO e Inforcarbono.
La Serie de Producción Agrícola Estadística (SEPA) es información recopilada por el Ministerio de Agricultura de Perú y disponible para el público. Contiene series de datos sobre precios, producción, rendimiento y superficie cosechada para cada departamento y para cada cultivo en el país, desde XX hasta XX. Los datos contenidos en SEPA son una aproximación a valores reales y pueden existir posibles diferencias importantes con la realidad. Se puede encontrar en el siguiente frenteweb.
La Encuesta Nacional Agraria (ENA) es una encuesta con datos disponibles por año desde 2014 hasta 2018. Esta encuesta es realizada por el Instituto Nacional de Estadística e Informática. ENA incluye información por año sobre los costos agrícolas: pesticidas, semillas y fertilizantes. Los datos de ENA se recopilan anualmente, por lo tanto, los datos de inversión no están disponibles durante largos períodos de tiempo. En este sentido, los datos de ENA representan los gastos corrientes asociados al sector agrícola. Los datos de la ENA se pueden descargar del siguiente iinei.
El CENAGRO es un censo del sector agrícola peruano y la fuente de datos más confiable de la que se dispone, fué aplicado por el Instituto Nacional de Estadística e Informática en el 2012. Lamentablemente no han sido actualizados aún, por lo que los datos no son totalmente representativos de nuestro año base. Por otro lado, el CENAGRO carece de datos de costos, lo cual es esencial para el modelo de simulación POLYSYS. Se puede descargar en el siguiente iinei.
Inforcarbono es una metodología para calcular las emisiones de cada cultivo y del sector ganadero. Es un consolidado en que se presenta una hoja de calculo donde diversos factores se aplican sobre distintas variables de cada sector. Esta metodología permite obtener linealidad en los cálculos de emisiones, por lo que será más fácil incorporarlos en la simulación POLYSYS.
El modelo, para sus proyecciones, agrupa categorías de cultivos en lugar de analizar cultivos específicos, por ejemplo la categoría tubérculos incluye papa, camote y yuca. De esta forma es necesario construir precios, rendimientos y costos para todas estas categorías de cultivos de forma conjunta. Para hacerlo se usó como ponderador al valor de la producción de cada cultivo que compone una categoría dentro de la región.
Por ejemplo en el caso de los tubérculos se halló el valor de la producción nacional del camote, de la papa y de la yuca. Posteriormente se agregó el valor de los tres cultivos y se encontró el valor de la producción nacional de los tubérculos. Finalmente usando el valor de la producción de cada componente de la categoría se halló el cual era la importancia de cada cultivo dentro de su categoría.
Usando la información de la SEPA, del MINAGRI, se utiliza los pesos previamente hallados y se encuentra un precio a nivel nacional por cada categoría. Evidentemente este procedimiento fue necesario, únicamente, cuando una categoría se compone por más de un cultivo. Estos mismos pesos se usaron para encontrar los rendimientos y costos para todas las categorías de cultivo.
Como mencionamos, nuestra propuesta se organiza en torno a simulaciones de dos sectores: agricultura y ganadería. Para el sector agrícola, modelamos la oferta, la demanda y su interacción respectiva en el mercado. Para el sector ganadero utilizamos un modelo combinado, que se basa en la función de crecimiento logístico de la población, una estimación econométrica de la oferta (sacrificio) y una simulación y la demanda de carne de res, de pollo y leche mediante una aproximación resultante de la solución de un sistema de ecuaciones. Los resultados del sector forestal, se vinculan a la actividad agrícola en la región amazónica al variar la tierra agrícola disponible, esto es resultado de la deforestación y reforestación de la zona. De manera similar las tierras destinadas para pastos ingresan como un input al modelo ganadero y modifican la capacidad de soporte vital total de la región selva. La dinámica del modelo se puede apreciar en el gráfico 2.
Finalmente es importante mencionar que el objetivo de la simulación es realizar predicciones hasta el año 2050, partiendo del año 2016. Teniendo al año 2016 como año base de la simulación y todos los inputs, para todos los sectores, serán datos de dicho año.
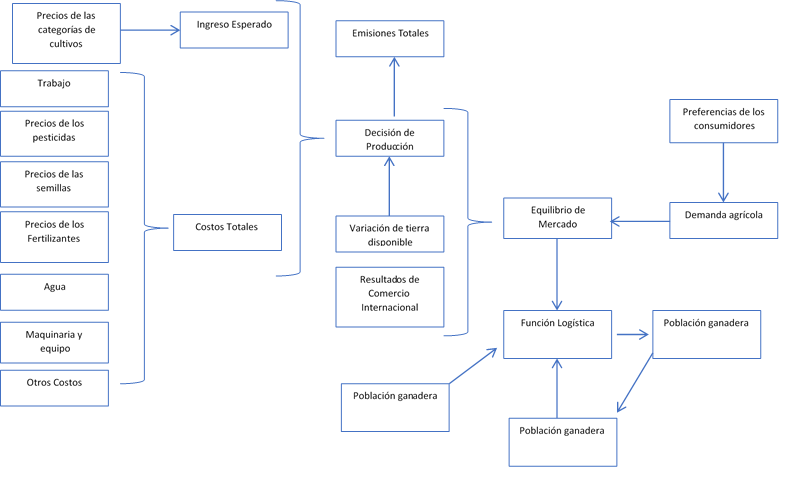
Figura 1 - Imagen 3
Para esta sección, se ha decidido utilizar la siguiente notación:
-El subíndice 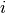 denota una categoría agrícola, como se tienen 14 categorías distintas entonces
denota una categoría agrícola, como se tienen 14 categorías distintas entonces
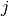 denota una categoría de ganado, como se tienen 3 categorías distintas entonces
.
-El subíndice
denota una categoría de ganado, como se tienen 3 categorías distintas entonces
.
-El subíndice  denota una región, como se tienen 7 categorías distintas entonces
.
-El subíndice
denota una región, como se tienen 7 categorías distintas entonces
.
-El subíndice 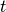 denota el tiempo, dado que se hará una simulación hasta el año 2050, y el punto de partida es el 2016, entonces :math: t∈{1,2,…,50}`.
-La constante
denota la tasa de cambio de uso de la tierra agrícola.
-La constante
denota el factor de descuento, que toma el valor de 0.91
-La variable
denota el tiempo, dado que se hará una simulación hasta el año 2050, y el punto de partida es el 2016, entonces :math: t∈{1,2,…,50}`.
-La constante
denota la tasa de cambio de uso de la tierra agrícola.
-La constante
denota el factor de descuento, que toma el valor de 0.91
-La variable 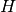 denota tierra
-La variable
denota tierra
-La variable 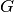 denota ganado vacuno
-La variable
denota ganado vacuno
-La variable 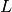 denota ganado lechero.
-La variable
denota ganado lechero.
-La variable 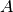 denota aves
-La variable
denota aves
-La variable 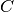 denota costo por hectárea agrícola
-La variable
denota costo por hectárea agrícola
-La variable 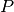 denota precios de los cultivos.
-La variable
denota precios de los cultivos.
-La variable 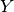 denota el rendimiento de la tierra.
-Las variables de tierra con una barra superior indican el total de tierra cultivable disponible.
-Las variables de tierra con dos sobre la barra indican el pasto total disponible.
denota el rendimiento de la tierra.
-Las variables de tierra con una barra superior indican el total de tierra cultivable disponible.
-Las variables de tierra con dos sobre la barra indican el pasto total disponible.
A partir de ahora, el índice asociado a cada variable o constante caracterizará las cualidades que queremos expresar .
Sobre el modelo propuesto en el capítulo 2 y sabiendo el total de divisiones regionales (7 regiones), de categoría de productos agrícolas (14 categorías) y de categorías de productos ganaderos (3 categorías) tenemos que la aplicación a la economía peruana implica que la oferta debe simular las decisiones de inversión agregada de los agricultores y ganaderos en cada región, como resultado estamos simulando las decisiones económicas de las 7 regiones en cada período de tiempo t. Intuitivamente, esto significa que en cada año una región decide cuántas tierras se dedican a cultivar cada cultivo, así como indicar cuanto ganado se sacrificará y en cuanto crecerá el total de cabezas de ganado. Esta decisión está limitada en dos sentidos:
Primero la tierra total disponible en cada región, para agricultura y para ganadería:
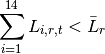
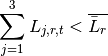
Segundo considera la limitación en el cambio del uso de la tierra agrícola de un período al siguiente:
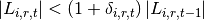
La tasa de cambio se determina de manera aproximada como un promedio de la tasa de variación del uso de la tierra de los últimos cinco años y posteriormente se ajusta de acuerdo a las necesidades que pueda requerir la simulación. Como ya se mencionó intuitivamente estas restricciones simulan la elasticidad de la oferta, ya que indica la capacidad de la oferta para sustituir un producto por otro. Por otro lado, suponemos que la capacidad de previsión de los agricultores es limitada, por lo cual basan sus decisiones en expectativas adaptativas donde el precio esperado para este período es el precio del período anterior. Es decir:
![E\left[P_{i, r, t}\right]=P_{i, r, t-1}](_images/math/ff653657dd4792701992902af44b747ed4c87efd.png)
En este punto resulta útil mencionar que los productos permanentes, en el problema de programación lineal que presentamos a continuación, debe considerar que el espacio temporal es distinto dependiendo el tipo de producto que se cultivará. En tal sentido las frutas de consumo doméstico, de exportación y la categoría de café y cacao son productos permanentes mientras el resto son considerados productos transitorios. Como simplificación el espacio temporal de los productos transitorios se considerará un año. De esta manera lo que, intuitivamente, estamos diciendo es que un agricultor decide cultivar un producto al inicio del año y al final del mismo lo cosecha y vende. En cambio, un producto permanente tiene un comportamiento más parecido al de una inversión de mediano y largo plazo, donde la decisión de cultivar un producto se toma en el presente, sin poder modificarla hasta que la planta haya cumplido todo su ciclo vegetativo. El cuestionamiento que surge de esto es saber cuál es el ciclo vegetativo correcto para los cultivos permanentes en el Perú. Sin embargo, cuando se hicieron indagaciones se encontró que los ciclos de cada cultivo eran muy diversos, y por tanto el ciclo para cada categoría era muy difícil de obtener. Por ejemplo, en el caso del café se encontraron distintos tipo de plantas de café, existiendo variedades que tenían un ciclo que rondaba entre los 20 y 25 años, sin embargo también se encontró que había otra variedad, que es la más utilizada hoy en día, y cuyo ciclo vegetativo rondaba los 10 años. Por lo tanto, debido a la fuerte heterogeneidad que existe entre los cultivos que componen cada categoría se decidió que el ciclo vegetativo de todos los cultivos permanentes sería de 12 años para la simulación. Otro aspecto a tener en cuenta es la rigidez de los cultivos permanentes después de ser cultivados. En tal sentido después que una región decide destinar cierta cantidad de tierra al cultivo de una categoría permanente, esta tierra no podrá ser dedicada a otro cultivo durante 12 años. Además, una vez que los cultivos permanentes, requieren de un tiempo mínimo durante el cual debe permanecer plantado, sin producir ningún retorno. Como simplificación se consideró que este tiempo, en el caso todos los cultivos permanentes, se reduce al primer año. La decisión de inversión resulta de una maximización de ganancias, que está representada por el siguiente problema lineal del programa:
![\max _{L_{i, t}}\left\{E\left[\Pi_{r}\right]=\sum_{t=1}^{12} \rho^{t} \sum_{i=1}^{14} L_{i, r, t}\left(Y_{i, r, t} E\left[P_{i, r, t}\right]-C_{i, r, t}\right)\right\}](_images/math/45b16cb73882813c9dcc61fc10ca2fd43bcb5543.png)
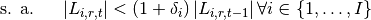
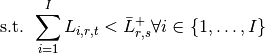
Esta optimización se aplica en cada período (año); además el total de tierra disponible depende también de cuántas hectáreas de cultivos permanentes se han cultivado en años anteriores. Esto se debe la restricción que existe una vez un cultivo permanente ha sido cultivado. Queda claro que una vez han pasado 12 años, la tierra destinadas a dichos cultivos permanente queda libre para poder asignarse a otros cultivos.
3.4.3 Contribuciones Nacionalmente Determinadas
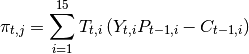
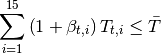
Vamos a determinar el arroz como
el nuevo método de cultivo de arroz como luego para cualquier tenemos: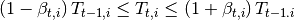
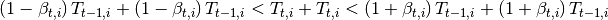
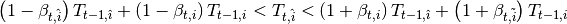
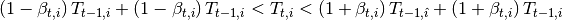
3.4.4 Descarbonización Profunda
- Este documento pretende ser una guía del código POLYSYS implementado en matlab. Antes de iniciar es importante hacer algunas menciones de forma:
Para todas las variables que se crean en el modelo, primero se generan como variables llenas de ceros; y después se llenan con los datos que se desea. Por nomenclatura todas las variables referidas al sector agrícola tienen la palabra Agri al inicio y las variables referidas al sector ganadero tienen las letras LS.
Las dos variables principales son:
AgriData: La variable que contiene toda la información relevante (inputs y outputs) para el sector agrícola
LSData: La variable que contiene toda la información relevante (inputs y outputs) para el sector ganadero
Ambas variables siguen un patrón claro de la presentación de los datos; ambas son un arreglo de dimensión 4 que sigue la siguiente estructura :
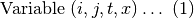
Donde:
i representa la categoría de producto
j representa la región
t representa el año
x representa la variable a usar; por ejemplo, ha de tierra, producción, costos, cabezas de ganado, etc.
En los dos sectores que se analizan se tiene lo siguiente
AgriNumberCategories: Indica el número de categorías de cultivo que hay en el sector agricultura, en este caso son 14.
LSNumberCategories: Indica el número de categorías de cultivo que hay en el sector ganadería, en este caso son 3.
En el sector agrícola tenemos la siguiente categorización:
Tabla 1. Índices Correspondientes a Categorías de Cultivo
Valor del Índice |
Categoría de Cultivo |
|---|---|
número 1 |
Alfalfa |
número 2 |
Legumbres |
número 3 |
Maíz |
número 4 |
Tubérculos |
número 5 |
Frutas de consumo doméstico |
número 6 |
Vegetales de consumo doméstico |
número 7 |
Frutas de exportación |
número 8 |
Vegetales de exportación |
número 9 |
Cacao y café |
número 10 |
Maíz amarillo duro |
número 11 |
Caña de azúcar |
número 12 |
Arroz |
número 13 |
Algodón |
número 14 |
Cereales y granos |
En el sector ganadero tenemos la siguiente categorización:
Tabla 2. Índices Correspondientes a Categorías Animal
número 1 |
Cabezas de ganado |
número 2 |
Cabezas de ganado lechero |
número 3 |
Aves |
Es denotado por j en el modelo. Para todo el modelo el total de regiones a analizar es 7: costa norte, costa centro, costa sur, sierra norte, sierra centro, sierra sur y selva. El número de regiones a analizar se define como: NumberRegions.
El modelo hace un análisis que inicia con el año base en 2016 hasta el 2050; se tiene un total de 34 años de simulación y uno de base. El número de periodos se define como: NumberPeriods
Para el sector agrícola tenemos:
Tabla 3. Índices Correspondientes a Variables del Sector Agrícola
número 1 |
Tierra |
número 2 |
Rendimiento |
número 3 |
Costo |
número 4 |
Precios |
número 5 |
Demanda o consumo |
número 6 |
Rendimiento |
número 7 |
Incremento en costo |
número 8 |
Tasa de variación de la tierra hacia abajo |
número 9 |
Tasa de variación de la tierra hacia arriba |
número 10 |
Tierra que acota la tierra hacia abajo |
número 11 |
Tierra que acota la tierra hacia arriba |
número 12 |
Consumo per cápita |
número 13 |
Calorías per cápita |
número 14 |
Producción agrícola |
número 15 |
Valor presente neto |
número 16 |
Valor de la producción |
número 17 |
Resultados de mercado internacional en producción |
número 18 |
Resultados de mercado internacional en valor |
Número 19 |
Factor agregado de emisiones |
Número 20 |
Factor de emisiones de arrozales anegados |
Número 21 |
Factor de emisiones de residuos de cosecha |
Número 22 |
Factor de emisiones de fertilizantes sintéticos |
Número 23 |
Factor de emisiones de fijadores |
Número 24 |
Factor de emisiones de quema de residuos |
Número 25 |
Factor de emisiones de fertilizantes indirectos |
Número 26 |
Total agregado de emisiones |
Número 27 |
Total de emisiones arrozales anegados |
Número 28 |
Total de emisiones de residuos de cosecha |
Número 29 |
Total de emisiones de fertilizantes sintéticos |
Número 30 |
Total de emisiones de fijadores |
Número 31 |
Total de emisiones de quema de residuos |
Número 32 |
Total de emisiones de fertilizantes indirectos |
Para el sector ganadero tenemos:
Tabla 4 Índices Correspondientes a Variables del Sector Ganadero
número 1 |
Cabezas |
número 2 |
Incremento en el número de cabezas |
número 3 |
Costo |
número 4 |
Saca (oferta o matanza) |
número 5 |
Consumo |
número 6 |
Emisiones |
número 7 |
Precios |
número 8 |
Pastos |
número 9 |
Factores explicativos de los precios |
número 10 |
Factores explicativos de los costos |
número 11 |
Carga viva |
número 12 |
Capacidad natural para soportar una población |
El modelo requiere ciertos inputs complementarios para la simulación:
Población: La población se define en base a los resultados predictivos del modelo T21. En el programa consiste en un vector de dimensión 1x35. La variable población se denomina: Population.
PBI: El PBI se define en base a los resultados predictivos del modelo T21. En el programa consiste en un vector de dimensión 1x35. La variable PBI se denomina: GDP.
Distribución de la población: Se tiene una distribución de la población entre las 7 regiones. La variable de distribución de la población se llama PopDistribution.
Otras variables son elementos que ingresan al modelo pero que fueron calculados a partir de información que ingresada previamente. Tenemos:
RegionalPop: Se calcula la población para cada región mediante la función AssignPopulation. Lo que hace esta función es tomar como inputs la población total (Population) y multiplicarla por PopDistribution.
GDPperCapita: Representa el PBI per cápita en el modelo; se calcula usando como inputs el PBI (GDP) y la población (Population).
ConsumptionPerCapita: Representa el consumo por individuo en peso del producto de cada categoría de cultivo.
EnergyConsumption: Representa el consumo de energía por individuo de cada categoría de cultivo.
AggregatedEnergyConsumption: Es el consumo agregado de energía per cápita.
La simulación se divide en tres subniveles:
Ingreso de información (inputs)
Tratamiento a la data (Solución del problema del problema de programación lineal y de la función logística).
Generación de output.
La transferencia de datos incluye dos secciones, la primera relacionada a información que no se almacena en las variables Agridata ni LSddata. La segunda a información que se almacena en las dos variables principales. La siguientes variables de carácter general se incluyen en la transferencia de datos inicial que no pertenece a Agridata ni LSddata. Tenemos:
Population: La población proyectada hasta el 2050 del modelo T21.
GDP: El PBI proyectado hasta el 2050 del modelo T21.
DiscountFactor: El factor de descuento para traer a valor presente cualquier valor dentro del modelo. Este es estático y toma el valor de 0.92, siendo un input del modelo.
AgriLandUseDomFruits, AgriLandUseExpFruits y AgriLandUseCandC: Estas variables indican la distribución de la tierra destinada a cultivos permanentes entre los 12 años del ciclo vegetativo. De esta forma se incorpora cuanta tierra está en su primer año, en su segundo año y así sucesivamente.
AgricultureLandbyRegion: Denota el máximo de tierra disponible para fines de agricultura para cada región
AgriElasticities: Se genera como un arreglo de tres dimensiones, en el cual el primer y segundo elemento representa las categorías agrícolas, el tercer elemento denota al tiempo. Se puede entender como un grupo de 35 matrices de dimensión 14x14.
LSElasticities: Se genera como un arreglo de tres dimensiones, en el cual el primer y segundo elemento representa las categorías ganaderas, el tercer elemento denota al tiempo. Se puede entender como un grupo de 35 matrices de dimensión 3x3.
La población y el PBI (líneas 161 y 163):
Population = xlsread('BAU.xlsx','General','C3:AL3');GDP = xlsread('BAU.xlsx','General','C4:AL4');La tierra correspondiente a cada región (líneas 206, 239, 249 y 251)
DiscountFactor = xlsread('BAU.xlsx','Agriculture','N6');AgricultureLandbyRegion = xlsread('BAU.xlsx','Agriculture','N4:T4');Elasticities(:,:,1) = xlsread('BAU.xlsx','Agriculture','N21:AA34');LSElasticities(:,:,1) = xlsread('BAU.xlsx','Livestock','L16:N18');En cuanto a la información que se destina a AgriData y LSData, esta ingresa al modelo mediante la función BAUTransferData. Esta función no tiene inputs de información agrícola o ganadera; sus únicos inputs están relacionados con la información general del modelo: número de regiones, número de periodos a simular, número de variables tanto para agricultura como para ganadería. Esta función simplemente se encarga de descargar toda la información de los file originales y la coloca en las variables principales AgriData y LSData. Por ello toda la información descargada aquí tiene la estructura apropiada para ser guardada dentro de variables estructuradas como (1).
Transfers agiculture and livestock data from database to the code[AgriData, LSData]=BAUTransferData(AgriNumberCategories,LSNumberCategories,...NumberRegions,NumberPeriods,AgriNumberVariables,LSNumberVariables);Una vez que la información ingresa al modelo, las variables AgriData y LSData están listas para recibir tratamiento y realizar cálculos.
En primer lugar, dado que existen categorías de cultivos permanentes, la tierra dedicada a estos cultivos estará dividida en porciones que estarán en distintas etapas (años) de su ciclo vegetativo. Para el modelo es necesario tener una variable que indique cuanta tierra está en cada etapa (año) para cada cultivo. Como ya se mencionó se tienen tres cultivos permanentes: frutas de consumo doméstico, frutas de exportación y café. Esta tierra se guarda, en detalle por año, en las variables:
AgriLandUseDomFruitsAgriLandUseExpFruitsAgriLandUseCandCComo se mostró en la sección anterior para el primer año (2016) se asigna la tierra de manera manual; como un dato más del inicio de la simulación. Posteriormente se reasignará la tierra en cada simulación (para cada año) de tal forma que se pueda hacer una redistribución en base a los cambios agregados de la tierra. Esta tierra irá cambiando año a año de acuerdo a los resultados de la simulación. Consideremos un ejemplo, supongamos que un cultivo cualquiera tiene 1´216 ha divididas para cada año de su ciclo vegetativo, en el segundo año esta distribución varía porque la tierra que estaba en el último año vuelve a estar libre para usarse en otros cultivo; la tierra que estaba en el primer año, pasa a estar en su segundo año y así sucesivamente. La tierra nueva que se cultiva de los cultivos permanentes pasa a estar en su primer año. Para entender mejor esta dinámica podemos observar la tabla 5, a continuación:
Tabla 5
Año 1 |
100 |
132 |
140 |
98 |
Año 2 |
100 |
100 |
132 |
140 |
Año 3 |
100 |
100 |
100 |
132 |
Año 4 |
100 |
100 |
100 |
100 |
Año 5 |
100 |
100 |
100 |
100 |
Año 6 |
100 |
100 |
100 |
100 |
Año 7 |
100 |
100 |
100 |
100 |
Año 8 |
100 |
100 |
100 |
100 |
Año 9 |
100 |
100 |
100 |
100 |
Año 10 |
100 |
100 |
100 |
100 |
Año 11 |
102 |
100 |
100 |
100 |
Año 12 |
114 |
102 |
100 |
100 |
Total |
1216 |
1234 |
1272 |
1270 |
Los datos ficticios aquí ayudan a observar la dinámica de cambio. Primero se tiene las 114 ha que el primer año de simulación estaban en su último año de ciclo vegetativo vuelven a estar libres, de tal forma que se pueden utilizar en el mismo cultivo o en uno distinto. Luego todas las ha avanzan un año en el ciclo vegetativo, las 102 ha del año 11 pasan al año 12, las 100 que estaban en el año 10, pasan al 11 y así sucesivamente. De la simulación se ha decidido el agregado de tierra que se destinará al cultivo permanente, de esta forma si se ha decidido que el total de tierra del cultivo permanente se incremente entonces la tierra nueva será mayor a la tierra que se dejó de usar en el cultivo permanente. Por ejemplo en nuestro ejemplo 114 ha se dejan de usar en el primer año de simulación pero se agregan 132, de esta forma en agregado se ha incrementado 18 ha. Asimismo en el ejemplo se puede observar que para el año 4 de la simulación el total de tierra ha disminuido, esto quiere decir que la tierra que se agrega es menor que la tierra que queda libre para otros cultivos.
4.8.4. Los precios internacionales
En cuanto a los precios internacionales que se importan de los resultados del modelo de equilibrio general COFFEE, lo que se hace antes de iniciar propiamente con la simulación, es importar la data para los cultivos del 5 al 14 (productos agrícolas internacionales). Esta información se coloca en AgriData(:,:,:,4). Es decir, en el segmento correspondiente al precio para todos los periodos.
El ingreso de la información se realiza mediante la función IntPrices, cuyos inputs son el número de periodos y la propia matriz de precios a llenar (AgriData). Los datos de precios del modelo de COFFEE, ingresan como una matriz de 10x35 (diez productos y 35 años de resultados) y estos deben ser distribuidos en las 35 matrices que se generan dentro de AgriData. Por ejemplo AgriData(:,:,1,4) matriz que representa el año 2016, AgriData(:,:,2,4), matriz que representa el año 2017, …, AgriData(:,:,35,4), matriz que representa el año 2050.
Ahora es importante mencionar que la data de precios internacionales no está distribuida por región (costa norte, sierra sur, etc.). Por ello, se realiza el siguiente procedimiento:
Primero, cuando se transfirió la data mediante BAUTransferData, se incluyó transferir los datos de precios regionalmente para cada producto de tal manera que AgriData(:,:,1,4) fue llenada.
Segundo la función IntPrices, toma los indicies de precios importados del modelo COFFEE y saca la variación para cada año desde el 2016 hasta el 2050.
El tercer paso consiste en usar el vector de las variaciones acumuladas previamente encontradas y multiplicarlo por la matriz de precios regional de tal manera que se consigue llenar el precio regionalmente para todos los años de simulación.
A partir de este punto se genera un bucle, donde cada vuelta representa lo que sucede en un año, propiamente se podría decir que toda la dinámica que toma lugar dentro de este bucle representa toda la dinámica del modelo. Se realiza un tratamiento para cada sector; en el código la simulación de cada sector tiene un título en comentario que permite identificar la sección correspondiente.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%Agriculture Simulation%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%Livestock Simulation%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%4.8.5 Agricultura
El Valor Presente neto
El primer paso para el problema de agricultura es hallar el valor presente para el sector agrícola. Esto se realiza mediante el uso de la función TotalNPV (ver línea 359), lo inputs de esta función son: los precios (AgriData(:,:,t,4)), los rendimientos, por región y categoría de cultivo (AgriData(:,:,t,2)), los costos, por región y categoría de cultivo (AgriData(:,:,t,3)), el factor de descuento (DiscountFactor), y una variable que indica en qué posición del arreglo están ubicados los cultivos permanentes (PermanentCrops).
Propiamente la funciónTotalNPV utiliza a la función NPV para hallar el valor presente neto de cada categoría cultivo. La función NPV, usa como inputs los precios (AgriData(i,:,t,4)), los rendimientos, por región y categoría de cultivo (AgriData(i,:,t,2)), los costos, por región y categoría de cultivo (AgriData(i,:,t,3)), el factor de descuento (DiscountFactor), y un indicador de ser cultivo permanente o transitorio.
La función NPV lo que hace es hallar la sumatoria de los beneficios netos de cada año para los siguientes 12 años.
(DiscountFactor^t)*(AgriData(:,:,t,4).*(AgriData(:,:,t,2) - AgriData(:,:,t,3)))
siendo que t toma valores para los 12 años. Los detalles de la programación se muestran a continuación:
function V = NPV(P,Y,C,d,e)This function permit to find a category crop net present valueIf e is equal to 1 then the crop is permanentif e==1R=0;for i=1:12if i==1R = R - (d^(i-1))*C*3;elseR = R + (d^(i-1))*(P.*Y-C);endendend%If e is equal to 0 then the crop is transientif e==0R=0;for i=1:12R = R + (d^(i-1))*(P.*Y-C);endend%If e is different to 0 or 1 then an error is displayif(e~=1) && (e~=0)disp('error');endV = R;El condicional que se coloca al inicio (e==1 o e==0) verifica si la posición dentro del vector corresponde a un cultivo permanente o a un transitorio. Cuando es 1, es permanente y 0 es transitorio. La forma de hallar el valor presente en ambos difiere un poco debido a las condiciones estructurales propias de cada tipo de cultivo.
Por ejemplo por limitaciones de datos fue imposible obtener datos representativos de la inversión que requieren los cultivos permanentes. Por ese motivo se revisaron tesis sobre planes de negocio en el sector agrícola. Y se encontró que aproximadamente la inversión inicial era unas tres veces el valor del gasto corriente.
Debe notarse que en el programa el símbolo .* indica que se trata de un producto de matrices pero dato a dato. Por ejemplo:
![\left[\begin{array}{l}
2 \\
4
\end{array}\right] \cdot *\left[\begin{array}{l}
1 \\
2
\end{array}\right]=\left[\begin{array}{l}
2 \\
8
\end{array}\right]](_images/math/a0677cfda071831a6b531c1e8274631fcdaecaa8.png)
Se hacen los productos de esta forma porque se está sacando el valor presente para las 7 regiones de manera simultanea.
Como se puede observar, cuando la categoría de cultivo es permanente, el primer año automáticamente tiene un rendimiento igual a 0 y por tanto no hay ingresos, solo costos.
El LP y su solución
Una vez los valores presentes netos han sido hallados por región y por categoría de cultivo, entonces se puede proceder a hallar la solución del problema de programación lineal. Para este fin se utiliza la función Linprog, una función propia del MATLAB, cuya sintaxis que se describe así :
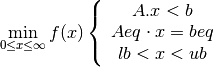
Tal como se observa, esta función minimiza una función lineal sujeta a restricciones de igualdad, y desigualdades lineales. La función se aplica de la siguiente forma:
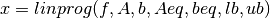
Siendo f la función a optimizar
A es la matriz de coeficientes de las ecuaciones que sirven como restricciones.
La letra b denota a los valores que toman estas ecuaciones.
Aeq es la matriz de coeficientes de las ecuaciones que sirven como restricciones.
La letra beq denota a los valores que toman estas ecuaciones.
El término lb denota las restricciones inferiores a las variables a optimizar.
El término ub denota las restricciones superiores a las variables a optimizar.
Primero se coloca la función a optimizar, posteriormente la matriz que representa las restricciones, después el valor de dichas restricciones. En el caso del sector agrícola en el POLYSYS se coloca lo siguiente (ver línea 379):
|AgriData(:,i,j+1,1)=linprog(-1*transpose(AgriData(:,i,j,15)),[],[],...
|AgriLandConstrains,AgricultureLandbyRegion(1,i),AgriData(:,i,j,10),AgriData(:,i,j,11));
En este caso los dos puntos que se ponen en la primera entrada de las variables hacen referencia a que se están tomando todos las categorías de cultivo al mismo tiempo; es decir un vector. La letra i denota región y la letra j el tiempo en este caso. Podemos, entonces, observar que AgriData(:,i,j+1,1), denota un vector. Por el valor 1 del índice que se utiliza en la cuarta entrada de la variable entonces AgriData(:,i,j+1,1) se refiere a la tierra cultivada y cosechada. Entonces AgriData(:,i,j+1,1) denota al vector de tierra que representa a todas las categorías de cultivo en la región i, en el periodo j+1.
En este caso por observar que el vector AgriData(:,i,j+1,1) es igual al resultado de la función linprog; es decir estamos hallando la tierra en el periodo siguiente j+1. Ahora en cuanto al uso propio de la función tenemos que:
La función f (función a optimizar) es -1*transpose(AgriData(:,i,j+1,15)). El negativo es porque lo que queremos es realizar una maximización, y como la función está diseñada para una minimización la forma de adaptarla es multiplicando todo por -1. Para fines expositivos tenemos lo siguiente:
-1*transpose(AgriData(:,1,1,15))=-1*[59499.12 6586.37 17519.52 -5877.41 40215.23 265877.10 58709.67 247895.73 -19838.60 -3823.85 44397.96 83.94 10013.21 -18568.92] Aquí se puede observar claramente que se tiene una vector de dimensiones 1x14, cada valor representaría el ponderador de cada incógnita en una función lineal dentro de un problema de optimización lineal.
El problema no tiene restricciones de desigualdad por eso los valores que están por notación de la función deben estar ocupados por A y b son reemplazados por [].
Las restricciones de igualdad son AgriLandConstrains=[1 1 … 1] que es igual a AgricultureLandbyRegion, el vector (1x14) de tierra que denota el total de tierra para cada región. Esto indica que la suma de la tierra cultivada de todas las categorías dentro de una misma región no puede ser mayor a la tierra disponible en la región.
Luego tenemos las restricciones de cambio propias de cada categoría de cultivo AgriData(:,i,j+1,10) y AgriData(:,i,j+1,11). Esto lo que indica es que la tierra cultivada de cada categoría no puede ser mayor ni menor del valor de la tierra multiplicada por uno más su tasa de flexibilidad.
Los resultados de la optimización son la tierra cultivada y cosechada en el periodo j+1.
Finalmente aquí es importante mencionar la redistribución de tierra en el caso de los cultivos permanentes que mencionamos anteriormente en la sección 4.8.3.
%Land is re-allocatedAgriLandUseDomFruits = AllocateLand(AgriLandUseDomFruits,AgriData(5,:,j+1,1));AgriLandUseExpFruits = AllocateLand(AgriLandUseExpFruits,AgriData(7,:,j+1,1));AgriLandUseCandC = AllocateLand(AgriLandUseCandC,AgriData(9,:,j+1,1));Se usa la función AllocateLand, la cual redistribuye la tierra entre los 12 años correspondientes y que serán input para la simulación del siguiente año. Esto sucede después de la optimización en la línea 395.
En este punto también se definen los nuevos limites a los cambios de tierra que serán usados en el siguiente periodo a simular (líneas 409 y 427):
AgriData(:,:,j+1,10) = (1+AgriData(:,:,1,8)).*AgriData(:,:,j+1,1); %Down limitAgriData(:,:,j+1,11) = (1+AgriData(:,:,1,9)).*AgriData(:,:,j+1,1); %Up limitEsto indica cuanto podrán crecer o disminuir las hectáreas asignadas a cada categoría cultivo en el siguiente periodo.
La oferta
Una vez la optimización ha sido realizada, se tienen los resultados de la tierra cosechada, la cual representa la oferta. Para hallar esto en términos de producción se utiliza la función AgriOuput de la siguiente manera:
AgriData(:,:,j+1,14)=AgriOutput(AgriData(:,:,j+1,1),AgriData(:,:,j+1,2),LandFirstYear(:,:,j));Los inputs de la función son:
1.La tierra total; es decir el resultado de LP (AgriData(:,i,j+1,1)) 2.El rendimiento AgriData(:,i,j+1,2) 3.La tierra de los cultivos permanentes que están en su primer año LandFirstYear(:,:,j)
La función AgriOuput (línea 442), encuentra el volumen de producción agrícola dada la cantidad total de tierra resultante del problema de optimización.
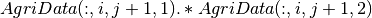
En esencia lo que hace esta función es multiplicar término a término las matrices de tierra (por cultivo y región) con la matriz de rendimiento (por cultivo y región).
La demanda
Dado que las variables de oferta han sido halladas en este punto es necesario hacerla interactuar con la demanda para obtener el resultado de equilibrio en el mercado. La interacción con la demanda se da a través de la función BAUFindEquilibrium. Esta función toma las variaciones de la oferta de los cultivos que se transan únicamente de manera interna y toma los precios internacionales y adapta el precio en el caso del primero y la demanda en el caso del segundo. La función tiene la siguiente notación:
[VarQD, VarPD] = BAUFindEquilibrium(AgriData,Elasticities,0.3,Population,GDP,j+1)Sus inputs son, la variable principal del sector agrícola, la matriz de elasticidades, la elasticidad ingreso (que toma el valor de 0.3), el vector de población, el vector de PBI y el periodo que se está simulando. Se puede ver el detalle a continuación:
function [VarQD, VarPD] = BAUFindEquilibrium(a,e,m,Pop,GDP,j,q,r)%a is the agriculture data%e is the elasticities matrix%m is the incom elasticity%Pop is the population%GDP is the GDP%j is the current periodVarP=zeros(14,1);b=a(:,:,j,14);b(12,1:3)=b(12,1:3)+q;c=a(:,:,j-1,14);c(12,1:3)=c(12,1:3)+r;VarQ = transpose(sum(transpose(b)))./transpose(sum(transpose(c)))-1;VarP(5:14,1)=a(5:14,1,j,4)./a(5:14,1,j-1,4)-1;CPop=Pop(1,j)/Pop(1,j-1)-1;CGDP=GDP(1,j)/GDP(1,j-1)-1;%Matrix for the domestic price determinated productsA=e(1:4,5:14,j);
|VarNQ=VarQ(1:4,1);
VarNQ = VarNQ-A*VarP(5:14,1)-CPop-m*CGDP;B=e(1:4,1:4,j);VarP(1:4,1) = linsolve(B,VarNQ);VarQD = e(:,:,j)*VarP + CPop + m*CGDP;VarPD = VarP;endEl detalle de lo que hace la función se presenta a continuación:
1.De la optimización y aplicación de la función AgriOuput sabemos cuánto es la producción de cada región. Dentro de esta función se agrega toda la producción por categoría de cultivo y posteriormente se obtiene cuanto ha sido la variación para el presente periodo. 2.Luego se encuentran los efectos (elasticidad multiplicada por variación de precio) que las variaciones de los precios internacionales generan sobre la demanda de los productos cuyos precios se determinan domésticamente.
VarNQ = VarNQ-A*VarP(5:14,1)-CPop-m*CGDP;3.Como se tiene la información de la variación de la oferta (producción) y del efecto de los precios internacional (que vendrían a ser constantes en esta sección) entonces se genera un sistema de ecuaciones a partir del cual se puede encontrar cuanto tienen que variar los precios para realizar el ajuste doméstico:
VarP(1:4,1) = linsolve(B,VarNQ);4.Una vez las variaciones de los precios domésticos se han encontrado, entonces es posible encontrar la variación de la demanda de productos transables. Esto se hace simplemente sumando la multiplicación de las elasticidades por las variaciones porcentuales de precios.
VarQD = e(:,:,j)*VarP + CPop + m*CGDP;El mercado Internacional
Una vez se ha hallado los resultados de producción y consumo entonces se procede a encontrar los resultados de mercado internacional,. E esencialmente encontrar cual es el resultado en cada categoría de producto agrícola. Esto se logra restando el consumo de la producción.
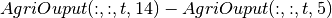
Estos resultados se guardan en AgriOuput(:,:,t,14). Propiamente es una resta simple de matrices. El resultado se interpreta como exportaciones si el resultado es positivo y como importaciones si el resultado es negativo.
Emisiones
Finalmente, en cuando a las emisiones se creó la función FindEmissions, la cual recibe como inputs la variable principal AgriData. Esta función multiplica los factores de emisión por la cantidad de tierra en cada año. Toma la siguiente sintaxis:
[AgriData(:,:,j+1,26), AgriData(:,:,j+1,27), AgriData(:,:,j+1,28), AgriData(:,:,j+1,29),AgriData(:,:,j+1,30), AgriData(:,:,j+1,31), AgriData(:,:,j+1,32)]= findEmissions(AgriData,j+1);Los inputs de esta función son: 1. Factores de emisión (todos los tipos) AgriData, las variables del 19 al 25. 2. Total de tierra para cada región y para cada categoría de cultivo.
Los resultados se guardan en AgriData, en las variables del 26 al 31.
3.2.2 Ganadería
Para la ganadería se utiliza el modelo mencionado en la sección teórica basado en una función de crecimiento poblacional logístico. Este modelo es ajustado por los pecios y costos del sector de tal manera que se genera una senda de crecimiento poblacional con fluctuaciones dependiendo de los cambios en precios y costos.
Determinantes de las Fluctuaciones
Las variaciones de precios (carne y leche) y costos (alfalfa y maíz amarillo duro) se obtienen dividiendo la senda de precios y costos del periodo actual respecto al periodo anterior:
%LSChangePrice=LSData(:,:,j+1,7)./LSData(:,:,j,7)-1;%Change in price%LSChangeCost(1,:)=AgriData(1,:,j+1,4)./AgriData(1,:,j,4)-1;%LSChangeCost(2,:)=AgriData(2,:,j+1,4)./AgriData(2,:,j,4)-1;%LSChangeCost(3,:)=AgriData(10,:,j+1,4)./AgriData(10,:,j,4)-1;En este sentido, en cada iteración estos resultados dependen de los resultados del modelo de agricultura (la variable 4); AgriData(i,j,t,4).
Variación en Pastos
El modelo incluye los resultados de pastos de la simulación forestal, de esta manera se agregan dichos en la selva generando variaciones en el total de tierra disponible.
LSData(1,7,j+1,8) = LSData(1,7,j,8)+LSShareGrassCows(1,7)*GrassResult(1,j);Capacidad del hábitat
Sobre este nuevo total de pastos se agrega la tierra cultivada de alfalfa como pastos. Entonces se determina la máxima capacidad de soporte del hábitat.
LSData(1,:,j,12)=LSData(1,:,j,12)+LSShareGrassCows.*AgriData(1,:,j+1,1).*AgriData(1,:,j+1,2)/10950;LSData(2,:,j,12)=LSData(2,:,j,12)+LSShareGrassDairyCows.*AgriData(1,:,j+1,1).*AgriData(1,:,j+1,2)/10950;Ecuación Logística
Posteriormente se incluyen todos los datos necesarios para el desarrollo de la ecuación logística:
El número de cabezas de ganado del periodo anterior (LSData(:,:,j,1))
Las tasas de crecimiento (LSData(:,:,j,2))
Las variaciones de precios y costos multiplicadas por sus ponderadores (LSChangePrice y LSChangeCost)
LSData(:,:,j+1,1)=LSData(:,:,j,1)+LSData(:,:,j,1).*((LSData(:,:,1,2).*(1-LSData(:,:,j,1)./LSData(:,:,j,12)))+LSData(:,:,1,9).*LSChangePrice+LSData(:,:,1,10).*LSChangeCost);La demanda
La demanda consiste en multiplicar la matriz de elasticidades de consumo por las variaciones de precio es decir LSElasticitiesxLSChangePrice.
LSConsumptionChange=LSElasticities(:,:,1)*LSChangePrice(:,1);3.3 Generación del Output
El ouput del modelo se escribe en tablas que son exportadas a archivos de texto. Esto se hace en la parte final de la modelación de la siguiente forma. 1. Primero se crean encuentran los datos nacionales para cada cultivo en cada año. Esto se hace, por ejemplo, sumando las hectáreas de cada cultivo en todas las regiones y agregándolas para obtener un valor nacional. Este valor se ajusta de acuerdo a la forma en que se quieren presentar los datos, por ejemplo, hectáreas cultivadas registradas en miles de ha por año. 2. Una vez encontrados los valores nacionales estos se guardan en una tabla. 3. El paso final es exportar los datos a un archivo de texto.
Los detalles de la programación se pueden ver a continuación:
| %%%%%Land%%%%%%
| Y2016 = transpose(sum(transpose(AgriData(:,:,1,1))))/1000;
| Y2020 = transpose(sum(transpose(AgriData(:,:,5,1))))/1000;
| Y2030 = transpose(sum(transpose(AgriData(:,:,15,1))))/1000;
| Y2040 = transpose(sum(transpose(AgriData(:,:,25,1))))/1000;
| Y2050 = transpose(sum(transpose(AgriData(:,:,35,1))))/1000;
'DomesticConsumptionVegetables' ...,'ExportFruits','ExportVegetables','CocoaandCoffee', 'YellowCorn', 'SugarCane', 'Rice',...'Cotton', 'CerealsandGrains'};TAgricultureLand = table(Y2016,Y2020,Y2030,Y2040,Y2050,'RowNames',CropNames);writetable(TAgricultureLand,'TAgricultureLand.txt'); type TAgricultureLand.txtEl ouput del modelo se escribe en tablas que son exportadas a archivos de texto. Esto se hace en la parte final de la modelación de la siguiente forma. 1. Primero se crean encuentran los datos nacionales para cada cultivo en cada año. Esto se hace, por ejemplo, sumando las hectáreas de cada cultivo en todas las regiones y agregándolas para obtener un valor nacional. Este valor se ajusta de acuerdo a la forma en que se quieren presentar los datos, por ejemplo, hectáreas cultivadas registradas en miles de ha por año. 2. Una vez encontrados los valores nacionales estos se guardan en una tabla. 3. El paso final es exportar los datos a un archivo de texto. Los detalles de la programación se pueden ver a continuación:
%%%%%Land%%%%%%Y2016 = transpose(sum(transpose(AgriData(:,:,1,1))))/1000;Y2020 = transpose(sum(transpose(AgriData(:,:,5,1))))/1000;Y2030 = transpose(sum(transpose(AgriData(:,:,15,1))))/1000;Y2040 = transpose(sum(transpose(AgriData(:,:,25,1))))/1000;Y2050 = transpose(sum(transpose(AgriData(:,:,35,1))))/1000;CropNames = {'Alfalfa','Corn', 'Legumes', 'Tubers','DomesticConsumptionFruits','DomesticConsumptionVegetables' ...,'ExportFruits','ExportVegetables','CocoaandCoffee', 'YellowCorn', 'SugarCane', 'Rice',...'Cotton', 'CerealsandGrains'};TAgricultureLand = table(Y2016,Y2020,Y2030,Y2040,Y2050,'RowNames',CropNames);writetable(TAgricultureLand,'TAgricultureLand.txt'); type TAgricultureLand.txt4. USCUSS¶
4.1 Modelamiento de flujos y stocks del bosque¶
En esta sección se evalúa los cambios de uso de suelo. El modelo consiste en un manejo de inventarios de stock de suelos de bosque primario, bosque secundario, tierra agrícola, pasturas, tierra para minería, asentamientos humanos y caminos, y otras tierras. Esto significa que las fuentes de deforestación de bosque reducen el stock de bosque, pero incrementan los stocks de otras tierras. No obstante, la información satelital no diferencia claramente la deforestación a causa de tala (madera y leña) y cualquier residual se reparte a tierra agrícola y ganadera. El diagrama a continuación ilustra las relaciones entre flujos y stocks.
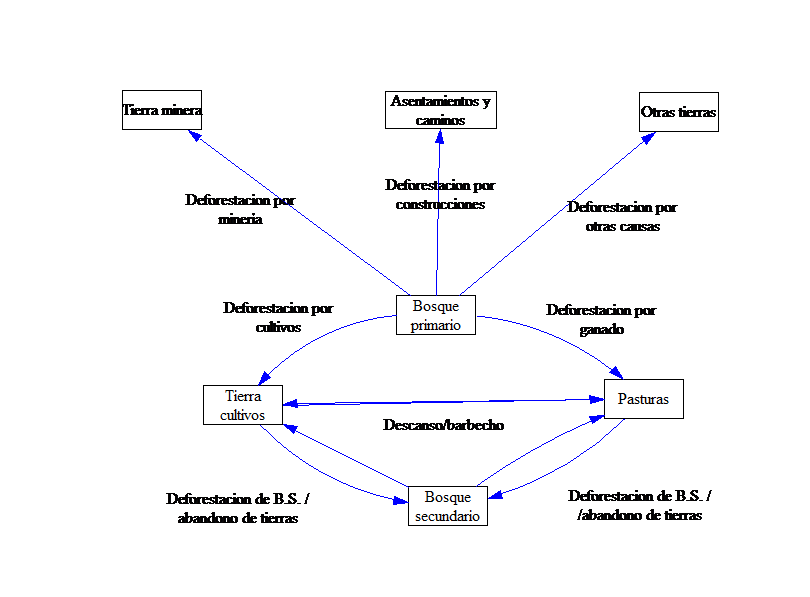
Relaciones de modelación de causas de deforestación. Fuente:propia
4.1.1 Modelamiento de causas de la deforestación¶
Como se mencionó el bosque primario, es el stock de bosque primario menos la deforestación. No se considera crecimiento de bosque primario.
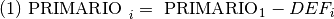
PRIMARIO, stock de bosque primario (hectáreas) en el año i.
PRIMARIO1, stock de bosque primario (hectáreas) en el año i.
DEF, flujo de deforestación (hectáreas) en el año i.
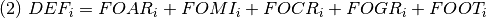
FOAR, flujo neto de cambio de tierras (Ha.) de bosque primario a asentamientos en el año i.
FOMI, flujo neto de cambio de tierras (Ha.) de bosque primario a minas en el año i.
FOCR, flujo neto de cambio de tierras (Ha.) de bosque primario a cultivos en el año i.
FOGR, flujo neto de cambio de tierras (Ha.) de bosque primario a pasturas en el año i.
FOOT, flujo neto de cambio de tierras (Ha.) de bosque primario a otros en el año i.
Se llama flujo neto porque cada flujo de deforestación tiene la posibilidad de ser reducida por las políticas NDC y DPP. En general, la reducción de deforestación se concentra en agricultura y, en menor medida, en minería y pasturas. Por ejemplo, en el caso de agricultura como causa, la deforestación neta sigue la siguiente forma:
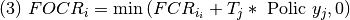
FOCR, flujo neto de cambio de tierras (Ha.) de bosque primario a cultivos en el año i.
T, es el activador de la política j (diferenciado por escenario NDC y DPP). Toma valores 0 y 1.
Policy, es el efecto de la política j en reducir la deforestación (Ha.) en la causa i.
La función es un mínimo porque no se permite el concepto de una deforestación negativa. Cada fuente de deforestación, con excepción de otras tierras es modelado mediante mínimos cuadrados ordinarios que consideran las siguientes variables:
Causa |
Parámetro |
|---|---|
Cultivo |
Población rural |
Cultivo |
Ingreso agrario neto promedio |
Cultivo |
Ingreso forestal neto promedio rezagado 1 período |
Cultivo |
Total de caminos pavimentados |
Pastura |
Ingreso forestal neto promedio |
Pastura |
Cabezas de ganado vacuno rezagado 1 período |
Pastura |
Caminos nacionales no pavimentados |
Asentamiento |
Constante |
Asentamiento |
Total de caminos pavimentados rezagado 1 período |
Minería |
Constante |
Minería |
Precio internacional del oro |
tabla 1: Parámetros de causas de deforestación
Por último, los demás stocks de tierra son acumulados de la siguiente manera:
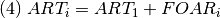
ART, asentamientos (Ha.) en el año i.
ART1, asentamientos (Ha.) en el año 1.
La excepción son tierras de cultivos y ganaderas, las cuales interactúan entre si y con bosques secundarios. Esto se detalla en la siguiente sección.
4.1.2 Modelación de barbecho¶
Los cultivos se dejan descansar y pasan a ser bosques secundarios o pasturas, y viceversa. Lamentablemente, la literatura no indica una práctica estándar en términos de tiempos. Se ha aplicado una proporción fija promedio del stock de tierras que pasan a las demás categorías.
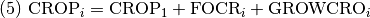
CROP, cultivos (Ha.) en el año i.
CROP1, cultivos (Ha.) en el año 1.
GROWCRO, crecimiento neto de cultivos (Ha.) en el año i.
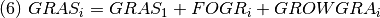
GRAS, pasturas (Ha.) en el año i.
GRAS1, pasturas (Ha.) en el año 1.
GROWGRA, crecimiento neto de pasturas (Ha.) en el año i.
Los crecimientos netos se definen como:
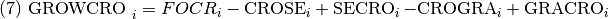
GROWCRO, crecimiento neto de cultivos (Ha.) en el año i.
CROSE, flujo de tierras (Ha.) de cultivos a bosque secundario en el año i.
SECRO, flujo de tierras (Ha.) de bosque secundario a cultivos en el año i.
CROGRA, flujo de tierras (Ha.) de cultivos a pasturas en el año i.
GRACO, flujo de tierras (Ha.) de pasturas a cultivos en el año i.
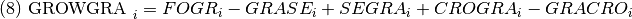
GROWGRA, crecimiento neto de pasturas (Ha.) en el año i.
CROGRA, flujo de tierras (Ha.) de cultivos a pasturas en el año i.
GRASE, flujo de tierras (Ha.) de cultivos a bosque secundario en el año i.
SEGRA, flujo de tierras (Ha.) de bosque secundario a cultivos en el año i.
GRACO, flujo de tierras (Ha.) de pasturas a cultivos en el año i.
Como se mencionó, la proporción de tierras que se transfieren es una proporción fija del stock. Esta proporción fija se calcula con el promedio histórico. Por ejemplo:
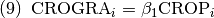
4.1.3 Modelación de bosque secundario¶
El suelo deforestado que se recupera se considera como bosque secundario. No obstante, las tierras mineras, asentamientos y otras tierras no son incluidos porque su aporte histórico es mínimo.
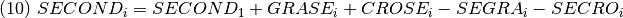
SECOND, bosque secundario (Ha.) en el año i.
SECOND1, bosque secundario (Ha.) en el año 1.
GRASE, flujo de tierras (Ha.) de cultivos a bosque secundario en el año i.
CROSE, flujo de tierras (Ha.) de cultivos a bosque secundario en el año i.
SEGRA, flujo de tierras (Ha.) de bosque secundario a cultivos en el año i.
SECRO, flujo de tierras (Ha.) de bosque secundario a cultivos en el año i.
4.1.4 Supuestos¶
Sólo un 25% de los bosques deforestados para cultivos son aprovechados. El resto es desperdiciado.
Algunas variables explicativas no fueron incluidas porque no resultaron significativas (como ingreso ganadero).
El precio internacional del oro hacia 2050 se calcula indirectamente empleado data futura de demanda de petróleo, precio de petróleo e índice de precios del dólar estadounidense.
No se incluye efecto de operativo Madre de Dios.
La deforestación por otros usos se calcula a través de la media móvil de los últimos cinco años.
Una fracción de deforestación por bosques secundarios va a agricultura.
Las ganancias forestales son fijas en el BAU.
El “rankeo” de cultivos en selva representa la transición de cultivos. Esto se trabaja en el modelo agrícola.
Las obras de pavimentación de caminos no pavimentados terminan en 2027 pues el Gobierno ha impulsado tal meta en la última década (se continua con la tendencia histórica).
4.2 Modelamiento de flujos y stocks del bosque¶
Los productos del bosque considerados son maderas provenientes de concesiones y plantaciones forestales y leña. En el caso de la leña, se utiliza la estimación futura de coeficientes de consumo per cápita estimado por CEPLAN.
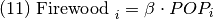
Firewood, leña (m3/ año) en el año i.
POP, población en el año i.
B, beta calculado por CEPLAN.
En el caso concesiones forestales, se busca obtener el ingreso neto de la actividad maderera. Se resume en la siguiente ecuación:
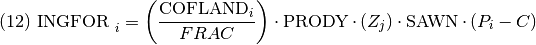
INGFOR, ingreso maderero de concesiones forestales (dólares) en el año i.
COFLAND, concesiones forestales (Ha.) en el año i.
FRAC, fracción de tierras activas.
PRODY, productividad (m3) por hectárea.
Z, vector de incremento de productividad bajo la política j (diferenciado por escenario NDC y DPP).
SAWN, proporción promedio de transformación de madera rolliza a aserrada.
P, precio de la madera (dólares/m3) en el año i.
C, costo de la madera (dólares/m3).
Análogamente, las plantaciones forestales comerciales también generan ingresos. Se trabajan con matrices pues las nuevas plantaciones no están listas para cosechar (toman 10 años en crecer).
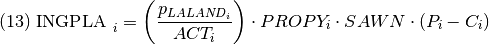
INGFOR, ingreso maderero de concesiones forestales (dólares) en el año i.
PLALAND, matriz de plantaciones forestales (Ha.) en el año i.
ACT, año de cosecha.
PROPY, matriz de productividad (m3) por hectárea de plantación en el año i.
SAWN, proporción promedio de transformación de madera rolliza a aserrada.
P, matriz de precios de la madera (dólares/m3) en el año i.
C, matriz de costos de la madera (dólares/m3) en el año i.
4.2.1 Supuestos¶
El valor de la madera se construye con un promedio ponderado de los valores ponderados. Su valor futuro se construye sobre la base de la proyección de índice de precios de productos madereros.
Los períodos de concesión se renuevan automáticamente.
Se asume un período de concesión promedio de 20 años.
En el escenario BAU se asume que la producción en concesiones maderables regresa a la máxima producción histórica entre el periodo 1990 y 2016.
Densidad de bosque tomada de INGEI 2012 para efectos del cálculo de emisiones de GEI.
Plantaciones forestales se dan en tierras eriazas.
La cosecha de plantaciones forestales son respuestas el mismo año (las tierras no quedan abandonadas.
Las plantaciones forestales consideran una especie de maduración de 10 años.
También se calculan las reforestaciones no comerciales. Estas solo acumulan los flujos de plantaciones del programa Agrorural.
Hay diferencias entre la estimación de leña de CEPLAN y la realizada por MINAM en el Inventario Nacional 2012. Se agregó un factor de ajuste de 0.5 para que la producción se asemeje a la reportada por MINAM.
4.3 Cálculo de deforestación por categoría de bosque¶
La proyección de deforestación total en el escenario BAU se reparte de acuerdo a la participación en deforestación (del último año) en 17 categorías de suelo: áreas naturales protegidas, conservación regional, conservación privada, bosque campesino, bosque de comunidades nativas, reservas territoriales, concesiones de madera, concesión de madera de alto rendimiento, reforestación comercial, concesión de conservación, concesiones de turismo, concesiones de fauna, concesiones de madera sin otorgar, bosque rural, humedales, concesiones de otros productos y sin categoría. Además, se han creado las siguientes categorías para efectos de las políticas: tierras eriazas, comunidades nativas eficientes y comunidades nativas con incentivos. Esta proyección de deforestación por categoría se expresa como proporción del año anterior de tal manera que la deforestación se expresa de la siguiente manera:
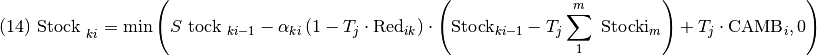
Stock, stock de bosque (Ha) de la categoría k en el año i.
∝, tasa de deforestación de la categoría k en el año i.
T, es el activador de la política j (diferenciado por escenario NDC y DPP). Toma valores 0 y 1.
Red, reducción de la tasa de deforestación de la categoría k en el año i.
Stocki, sumatoria de hectáreas de tierras que son transferidas de la categoría k a la categoría m.
CAMB, aumento o reducción directo de hectáreas en el año i.
Todas las variables vinculadas a políticas no aplican a todas las categorías. La reducción de stock por transferencia de tierras  aplica a las políticas de otorgación de derechos, incremento de tierras de concesión forestal de alto rendimiento y transferencia de comunidades nativas y eficientes. La reducción en la tasa de deforestación (〖Red〗_ik) aplica para las políticas de comunidades nativas. La variación directa en el stock se toma en cuenta para plantaciones forestales y áreas naturales protegidas.
Finalmente, se suman los stocks en cada año y se compara con el stock de bosque total de BAU. Esa variación es la variable Policy de la ecuación 3. Es necesario mencionar que esta sección no incluye la reducción adicional de deforestación proveniente de la mejora de ingresos forestales.
aplica a las políticas de otorgación de derechos, incremento de tierras de concesión forestal de alto rendimiento y transferencia de comunidades nativas y eficientes. La reducción en la tasa de deforestación (〖Red〗_ik) aplica para las políticas de comunidades nativas. La variación directa en el stock se toma en cuenta para plantaciones forestales y áreas naturales protegidas.
Finalmente, se suman los stocks en cada año y se compara con el stock de bosque total de BAU. Esa variación es la variable Policy de la ecuación 3. Es necesario mencionar que esta sección no incluye la reducción adicional de deforestación proveniente de la mejora de ingresos forestales.
4.4 Cálculo de deforestación por categoría de bosque¶
Las emisiones son calculadas con la metodología y parámetros propuestos por Inventario Nacional de Emisiones de GEI (Minam, 2012). A continuación, se lista que resultados del modelo son empleados para el cálculo de emisiones:
Crecimiento de la biomasa del bosque secundario.
Crecimiento de la biomasa de los cultivos.
Cosecha de cultivos como pérdida de reservas de carbono.
Transformación de bosque primario y secundario a cultivos.
Pérdida de carbono por remoción de tierras a causa de cultivos.
Pérdida de humedales a causa de cultivos.
Transformación de bosque primario y secundario a pasturas.
Pérdida de carbono por remoción de tierras a causa del ganado.
Pérdida de humedales a causa del ganado.
Transformación de bosque primario a asentamientos y caminos.
Transformación de bosque primario a tierras mineras.
Transformación de bosque primario a otras tierras.
Quema de bosques para obtención y/o fertilización de tierras de cultivos y pasturas.
Extracción de madera y leña.
Crecimiento de plantaciones forestales.
Si bien el inventario incluye los parámetros del crecimiento inherente de bosque primario, no se incluye en el reporte del inventario 2012.
Bibliografía GGGI. (2015). Interpretacion de la dinámica de la deforestación en el Perú y lecciones aprendidas para reducirla. Lima. Minam. (2012). Inventario Nacional de Gases de Efecto Invernadero. Lima.
4.5 Anexos¶
Categoria |
Parámetro |
Valor |
|---|---|---|
Cultivo |
Población rural |
0.046236 |
Cultivo |
Ingreso agrario neto promedio |
2.9868 |
Cultivo |
Ingreso forestal neto promedio rezagado 1 período |
-1.09119 |
Cultivo |
Total de caminos pavimentados |
28.8979 |
Pastura |
Ingreso forestal neto promedio |
-0.67113 |
Pastura |
Cabezas de ganado vacuno rezagado 1 período |
0.01817 |
Pastura |
Caminos nacionales no pavimentados |
30.7302 |
Asentamiento |
Constante |
-2804.3 |
Asentamiento |
Total de caminos pavimentados rezagado 1 período |
0.435591 |
Minería |
Constante |
1222.39 |
Minería |
Precio internacional del oro |
2.09236 |
Cultivo |
Tasa de cultivos a pasturas |
0.004375 |
Pastura |
Tasa de pasturas a cultivos |
0.002111 |
Bosque secundario |
Tasa de secundario a cultivos |
0.01253 |
Bosque secundario |
Tasa de secundario a pasturas |
0.002632 |
Cultivo |
Tasa de cultivos a secundario |
0.07 |
Pastura |
Tasa de pasturas a secundario |
0.008 |
Comunidades nativas (CCNN) |
Reducción de deforestación en CCNN |
0.3 |
Áreas Naturales Protegidas (ANP) |
reducción de deforestación en ANP |
0.5 |
Concesión maderable |
Rendimiento BAU bajo rendimiento (m3/Ha.) |
3.9 |
Concesión maderable |
Rendimiento BAU alto rendimiento (m3/Ha.) |
5.7 |
Concesión maderable |
Rendimiento máximo en NDC o DPP (m3/Ha.) |
8 |
Concesión maderable |
Periodo de concesión (años) |
20 |
Concesión maderable |
Área de reforestación activa (1/Período de concesión) |
0.05 |
Reforestación comercial |
Tiempo en cosechar (periodo) |
1 |
Reforestación comercial |
Área de reforestación activa (%) |
0.125 |
Reforestación comercial |
Rendimiento (m3/Ha.) |
40 |
Leña |
Coeficiente población |
2.778 |
Producción madera |
Tasa de conversión de madera rolliza a aserrada |
0.47 |
fuente: Valores de principales parámetros
Variable |
Unit |
Value |
|---|---|---|
Conversión en GG Ton CO2 |
GG Ton CO2 |
0.0037 |
Conversión CH4 |
DMML |
21.0 |
Conversión NO2 |
DMML |
310.0 |
Crecimiento biomasa en secundario |
TMS/HA |
11.80 |
Crecimiento de biomasa cultivos |
TMS/HA |
2.60 |
Materia seca |
DMML |
0.5 |
Reservas carbono suelos |
TC/HA/YEAR |
21 |
Carbono removido por cultivos |
TC/HA |
-126.77 |
Carbono removido por pasturas |
TC/HA |
-134.81 |
Carbono removido por otros |
TC/HA |
-293.5 |
Stock de carbono en bosque secundario |
TC/HA |
-71 |
Stock de carbono en cultivos |
TC/HA |
5 |
Stock de carbono en pasturas |
TC/HA |
8.1 |
Periodo de inventatio |
YEAR |
20 |
Carbono inicial en tierra AAA |
TC/HA |
65 |
Carbono inicial en tierra ABA |
TC/HA |
47 |
Perdidaa de carbono en tierra AAA por cultivos |
TC/HA |
46.56 |
Perdidaa de carbono en tierra AAA por cultivos |
TC/HA |
46.56 |
Perdidaa de carbono en tierra ABA por cultivos |
TC/HA |
33.67 |
Perdidaa de carbono en humdeales por cultivos |
TC/HA |
-20 |
Perdidaa de carbono en tierra AAA por pasturas |
TC/HA |
63.05 |
Perdidaa de carbono en tierra ABA por pasturas |
TC/HA |
45.59 |
Perdidaa de carbono en humdeales por pasturas |
TC/HA |
-5 |
Factor de biomasa quemada |
DMML |
0.5 |
Masa de bosque primario 1 |
DMML/HA |
208,643.00 |
Masa de bosque primario 2 |
DMML/HA |
222,819.00 |
Masa de bosque secundario |
DMML/HA |
100,000.00 |
NO2 factor |
DMML |
0.11 |
CH4 factor |
DMML |
9 |
Incremento medio anual de biomasa aérea |
t m.s. ha-1 año-1 |
13 |
Factor de conversión Raíz/Tallo apropiado a los incrementos |
DMML |
0.32 |
Emision de lenia |
3.4 |
|
Emision de extracción de madera |
1.67 |
Valores de principales parámetros de cálculo de emisiones